Backups
Access Backups
Learn how to access your backups.
This section provides information on how to access your backups from your Pantheon dashboard and the command line.
Pantheon backups are stored offsite on Google Cloud Storage instances. We recommend a full-fledged backup solution for retention. For example, the following script can be executed from an external cron job to send backups to your own Amazon S3 instance:
Access Backups Via the Dashboard
The jobs indicator returns to its start state to let you know that the task is complete when the backup finishes. A new backup appears in your Backup Log with three separate archives (code, database, and files).
The newest backup appears at the top of the list. A backup will no longer be in the list of available archives when the retention period expires.
-
Navigate to your site's dashboard.
-
Click Backups and then click Backup Log.
-
Click the down arrow next to Code, Database, or Files to access the link for the offsite backup.
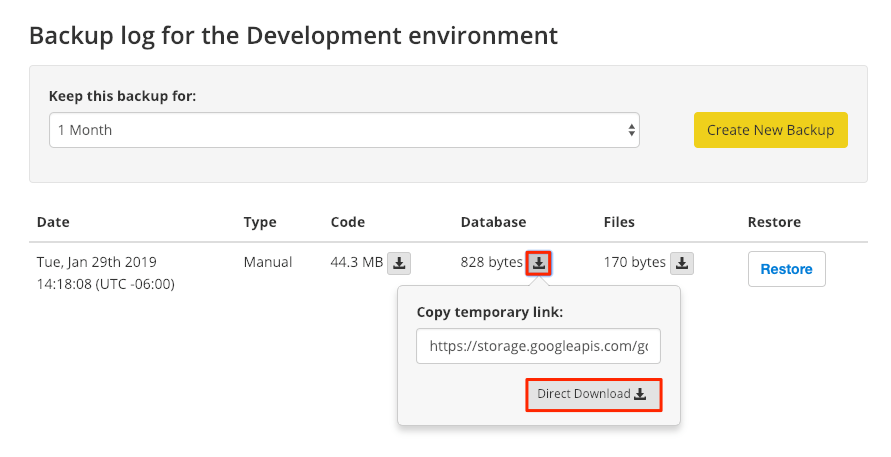
Some older versions of Google Chrome can cause database backups to be downloaded with incorrect file extensions (e.g. .sql instead of sql.gz). You can resolve this problem by updating Google Chrome or by renaming the file using the correct extension.
Access Backups Via the Command Line
You can copy the temporary URL provided via the Dashboard and download your backups from the command line using Wget or Terminus. Links to backups are assigned URLs directly from Google Cloud Storage and expire. Return to the Dashboard and get a new link to the archive if a link has expired.
Unix/MacOS
Windows
Wrap the URL in double quotes (") when using Wget in the Windows Powershell. The shell doesn't return any output until the download completes:
Terminus
Note that --element=all is only available when creating backups and not when downloading. Replace <selected_element> with either code, files, or db:
File and code backups are saved as .tar.gz, while database backups are saved as .sql.gz. Be sure to use the correct extension when specifying the file path for --to.
Select an older archive by running terminus backup:list $site.$env, copying the filename, and pasting it in the --file=<filename> option when downloading: